How to fine-tune a NLLB-200 model for translating a new language
“NLLB” (which stands for “no language left behind”) is a family of machine translation models published by Meta AI in 2022. These models can translate a sentence between any of the 202 language varieties, which is a huge research breakthrough. But there are about 7000 languages in the world, so most of them are still left behind so far.
How can we teach this model one more language? In this tutorial, I show it. As a demonstration, we will teach the model to translate between Russian and a low-resource Tyvan language, which is new to this model. The Russian language is Slavic, while Tyvan is a Turkic language with a lot of Mongolian influence. Therefore, while they are written in similar Cyrillic scripts, translating between them is not trivial. Nevertheless, thanks to the pretraining with 202 languages, NLLB can do it pretty well.
The full code of the tutorial can be found in this Colab notebook. The tutorial includes 8 steps:
- Looking at the training data
- Examining tokenization of the new language
- (Optionally) Updating the vocabulary
- (Optionally) Adding a new language token
- Training the neural model
- Evaluating the model
- Publishing
- (Optionally) Serving the model with a Docker app

Acknowledgements
This article wouldn’t have been written without Ali Kuzhuget, mathematician and iOS developer, creator of Tyvan Wikipedia, Tyvan mobile keyboard, and the Tyvan-Russian dictionary, who organized the collection of the parallel corpus used here for training. Many thanks to all the translators that contributed and keep contributing to the corpus.
I am grateful to Aira Mongush, ML enthusiast, founder of the Digital Tuva community, who inspired the team with the idea of this project, took the role of a team manager and helped make this text more readable and understandable.
A note about Tyvan
The Tyvan language, also known as Tuvan, is a member of the Turkic language family predominantly spoken in the Republic of Tuva, nestled in South-Central Siberia, Russia. With its roots deeply intertwined with the socio-historical fabric of the Tuva region, Tyvan has absorbed a plethora of lexical items from Mongolian, Tibetan, and Russian languages over centuries. Tyvan is classified as a Northeastern or Siberian Turkic language, sharing close linguistic kinship with other Siberian Turkic languages such as Khakas and Altai, offering a rich ground for comparative linguistic analysis. As of recent data, Tyvan is spoken by approximately 280,000 people, making it a key medium of communication within the Republic of Tuva.
The language, however, is listed as vulnerable by UNESCO’s Atlas of the World’s Languages in Danger, reflecting a need for linguistic preservation efforts to keep this cultural treasure alive. Engaging with Tyvan language data can not only enhance the robustness of the NLLB model but also contribute towards the digital preservation of a language that encapsulates a unique socio-historical narrative of the Eurasian Steppe.
Why NLLB?
It is one of the most popular publicly available translation models (according e.g. to the number of likes on HF), and probably the most multilingual one.
Alternatively, you may want to use open LLMs, such as LLaMA. In the last year, LLMs became popular for multiple tasks, including translation, and they are reported to translate into English better than NLLB. However, these models are at least x10 larger than the NLLB-200-600M checkpoint which we will fine-tune, and this makes their training and deployment more difficult and expensive. Also, the pretraining data for most LLMs is usually 90% or more English, so they may not generate texts so well in other languages, especially lower-resourced ones. Thus, we stick to NLLB.
Key concepts
In this section, I briefly list the terms that we will be using. If too many of them are unfamiliar to you, please consider doing some introductory reading (e.g. NLP course by Lena Voita) before proceeding with this article.
- Corpus: a diverse collection of texts (or, if it is a parallel corpus, of text pairs in two different languages).
- Normalization: conversion of something to its “normal” form, where “normal” is defined arbitrarily. For example, if we decide that quotation marks should look like
", then replacing«with"would be a normalization. - Token: a minimal unit of text with which a neural network operates. Their size is usually between a single character and a whole word with a space before it. Each model usually support a fixed set of tokens, called its vocabulary.
For example, the vocabulary of NLLB by default has 256204 tokens. The word"preprocess"is not in this vocabulary, but can be represented as 3 tokens,"▁pre" + "pro" + "cess", where"▁"is a substitute for space and it signals the start of a new word. These tokens occupy the positions 951, 4573, and 8786 in the vocabulary. - Tokenizer: a tool for converting texts into token ids (their positions in the vocabulary) and back.
- Embedding: a numerical vector that represents some object. In our case, embeddings are parts of the translation model and they represent tokens. For example, NLLB-200–600M model has 256204 embeddings (one per each token in its vocabulary), and they are 1024-dimensional vectors. Embeddings are trained together with the rest of the neural network.
Prerequisites
I assume that you are familiar with the Python programming language and the Google Colab environment. Ideally, you should also understand the Huggingface ecosystem (they have a good course about it).
To reproduce this tutorial, you will need a Tyvan-Russian parallel corpus, that is, a collection of translated sentences, phrases or words. You can download a version of it from https://tyvan.ru. This version contains 50K translation pairs, whereas the one I used in the notebook is larger, about 120K pairs, so my results won’t be reproduced exactly (update: now the full dataset is available here). Nevertheless, even 50K training pairs can be enough for decent translation.
If you want to use another language pair, you will have to find the data for it (at least a few thousand pairs; a few hundred thousand for really good translation). Two good spots to start the search are OPUS and HF datasets.
Originally, I ran the tutorial code in a Google Colab notebook with a Tesla T4 GPU (15Gb of memory). I fine-tuned the model for about 20 hours (50K training steps); running the notebook for this duration without interruption required from me a paid Colab subscription. Fine-tuning for a few hours can usually be done on a free plan; fine-tuning with less GPU memory may require adjusting the batch size.
To load the dataset and save the model, I use my Google Drive, which I mount to the /gd directory in Colab:
from google.colab import drive
import os
if not os.path.exists('/gd'):
drive.mount('/gd')For uploading the dataset, instead of Google Drive, you can just use the “upload” graphical interface of Colab (and change accordingly the path to the file in the code in the next section):
Before running my notebook, I install a few Python modules:
!pip install sentencepiece transformers==4.33 datasets sacremoses sacrebleu -qThe specific version transformers==4.33 is important, because the way I mingle with the tokenizer at the Step 4 depends on it. In the version 4.34, the package started introducing breaking changes to the tokenizer, and when these changes stabilize, the recommended code for updating the tokenizer will be different.
The steps for adding a new language to NLLB
Step 1: looking at the data
I start by reading the training dataset and taking a look at it:
import pandas as pd
trans_df = pd.read_csv('/gd/MyDrive/datasets/nlp/tyvan/rus_tyv_parallel_50k.tsv', sep="\t")
print(trans_df.shape) # (50000, 5)
print(trans_df.columns) # ['row_id', 'ind', 'tyv', 'ru', 'split']
trans_df.sample(10)Here is the output; tyv and ru are the columns with the translation pairs.
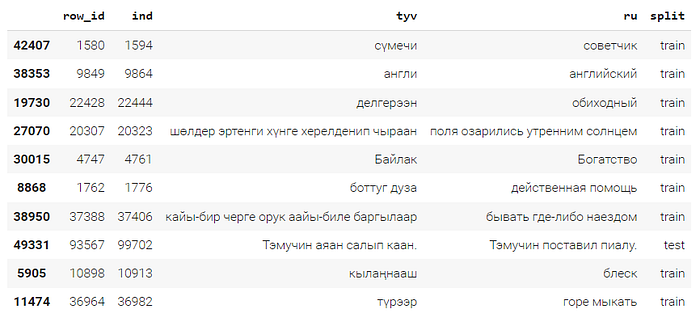
In this dataset, most of the texts are individual words or short phrases, and only a few of them are complete sentences. This is not typical for the machine translation data; normally it is collected on the sentence level. However, with low-resource languages, dictionaries may be a dominant data source, and they are constructed mostly on the word or phrase level, so such distribution of texts is not totally unusual. In any case, you need to make sure that the training texts do contain many diverse sentences, and that they look more or less clean and consistent. If there are longer training texts (e.g. paragraphs), it is recommended to split them in sentences (e.g. with this tool), and re-align them into translation pairs on the sentence level (e.g. with lingtrain-aligner or vecalign).
This dataset is pre-split into train, dev and test subsets. I did it previously with sklearn.model_selection.train_test_split ; in the training notebook, I load the splits into separate dataframes:
df_train = trans_df[trans_df.split=='train'].copy() # 49000 items
df_dev = trans_df[trans_df.split=='dev'].copy() # 500 items
df_test = trans_df[trans_df.split=='test'].copy() # 500 itemsStep 2: How well does the data fit into a NLLB tokenizer?
The NLLB models (as most of other modern NLP neural model) consist of 2 components:
- the tokenizer (a thing that splits the text into chunks and maps each chunk into a number, according to a pre-defined vocabulary);
- the neural network itself (it performs the translation based on these numbers and outputs some new numbers; then the tokenizer converts them back to texts).
So the translation always goes the way “input text -> input tokens -> translated tokens -> translated text”, like in this example:
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model_name = "facebook/nllb-200-distilled-600M"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
tokenizer.src_lang = "rus_Cyrl"
inputs = tokenizer(text="поля озарились утренним солнцем", return_tensors="pt")
translated_tokens = model.generate(
**inputs, forced_bos_token_id=tokenizer.lang_code_to_id["eng_Latn"]
)
print(tokenizer.decode(translated_tokens[0], skip_special_tokens=True))
# The fields were lit by the morning sun(If this code snippet intimidates you, please consider taking the Huggingface course before returning to this tutorial)
The quality of translation critically depends on how well the tokenizer represents our languages:
- How many tokens per word do we have on average? For a good translation quality, we usually want one token to represent a word or a morpheme, or at least something of a comparable size.
- Does the tokenizer support most of our vocabulary? All unsupported characters are converted to the special
<unk>token that carries very little information; many such cases again degrade the quality.
Tokenization is something that we can test before even touching the translation model itself. I extract a sample of the training data and count the number of words and tokens in it:
import re
def word_tokenize(text):
"""
Split a text into words, numbers, and punctuation marks
(for languages where words are separated by spaces)
"""
return re.findall('(\w+|[^\w\s])', text)
smpl = df_train.sample(10000, random_state=1)
smpl['rus_toks'] = smpl.ru.apply(tokenizer.tokenize)
smpl['tyv_toks'] = smpl.tyv.apply(tokenizer.tokenize)
smpl['rus_words'] = smpl.ru.apply(word_tokenize)
smpl['tyv_words'] = smpl.tyv.apply(word_tokenize)Now I can take a glance at the tokens. They look adequately (at least, to my subjective eye); the average of 2–3 tokens per word is typical for well-tokenized texts in morphologically rich languages, such as Russian or Tyvan.

Actually, we can compute precise statistics of this (they are explained here):
stats = smpl[
['rus_toks', 'tyv_toks', 'rus_words', 'tyv_words']
].applymap(len).describe()
print(stats.rus_toks['mean'] / stats.rus_words['mean']) # 2.0349
print(stats.tyv_toks['mean'] / stats.tyv_words['mean']) # 2.4234
stats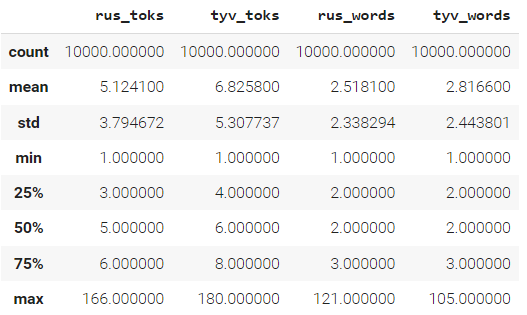
Good news: for Tyvan, a new language, the NLLB tokenizer produces on average 2.4 tokens per word; almost as few as 2.0 for the well-supported Russian language. This implies that the translation quality of fine-tuned NLLB may be decent without extending its vocabulary with Tyvan tokens.
Another useful check: how often does the <unk> token happen in the tokenizer output for Tyvan? If this is too often, we need to fix it somehow.
from tqdm.auto import tqdm, trange
texts_with_unk = [
text for text in tqdm(trans_df.tyv)
if tokenizer.unk_token_id in tokenizer(text).input_ids
]
print(len(texts_with_unk))
# 163
s = random.sample(texts_with_unk, 5)
print(s)
# ['Ынча деп турар болзуңза, сени кандыг далайжы дээрил?! – деп, Дриниан удурланган.'
# 'Ыяштап чоруй барган ачам келгеш, мени аажок мактаар боор: «Ёзулуг аңчы-дыр сен, оглум!»',
# 'Ажыл хуваарга — арыг кирер, ажык хуваарга — куруг үнер', ...We can see that out of 49K texts, 163 contain an “unknown symbol” after tokenization. Most of these cases seem to be associated with non-standard punctuation marks (as defined by MosesPunctNormalizer), and there is a reason for that: the NLLB team preprocessed their texts before training the tokenizer and the model. The code for preprocessing (adapted from the Stopes repo) looks like this:
import re
import sys
import unicodedata
from sacremoses import MosesPunctNormalizer
mpn = MosesPunctNormalizer(lang="en")
mpn.substitutions = [
(re.compile(r), sub) for r, sub in mpn.substitutions
]
def get_non_printing_char_replacer(replace_by: str = " "):
non_printable_map = {
ord(c): replace_by
for c in (chr(i) for i in range(sys.maxunicode + 1))
# same as \p{C} in perl
# see https://www.unicode.org/reports/tr44/#General_Category_Values
if unicodedata.category(c) in {"C", "Cc", "Cf", "Cs", "Co", "Cn"}
}
def replace_non_printing_char(line) -> str:
return line.translate(non_printable_map)
return replace_non_printing_char
replace_nonprint = get_non_printing_char_replacer(" ")
def preproc(text):
clean = mpn.normalize(text)
clean = replace_nonprint(clean)
# replace 𝓕𝔯𝔞𝔫𝔠𝔢𝔰𝔠𝔞 by Francesca
clean = unicodedata.normalize("NFKC", clean)
return cleanIf we apply this normalization before tokenizing the texts, all the “unknown” characters disappear.
texts_with_unk_normed = [
text for text in tqdm(texts_with_unk)
if tokenizer.unk_token_id in tokenizer(preproc(text)).input_ids
]
print(len(texts_with_unk_normed)) # 0To sum up, NLLB tokenizer produces tokens for Tyvan which are long enough, and successfully recognizes all Tyvan characters. I will use it as evidence that it is not neccessary to update the tokenizer’s vocabulary to use it with Tyvan.
Step 3 (optional): Expanding the vocabulary
As we have concluded on the previous step, expanding the tokenizer’s vocabulary is not necessary for Tuvan: there are no out-of vocabulary characters, and the average token length is comparable with that of a high-resource language (Russian). If this was not the case, we would have to add some new tokens for Tyvan into the tokenizer’s vocabulary (and into the neural network as well). This section explains how to achieve that.
I start by getting more Tyvan texts for training a Tyvan-specific tokenizer. These texts don’t have to be parallel with another language, so I just download a parsed version of the Tyvan Wikipedia. This triples the total length of the Tyvan texts I had:
from datasets import load_dataset
tyv_wiki = load_dataset("graelo/wikipedia", "20230601.tyv")
tyv_wiki
# DatasetDict({
# train: Dataset({
# features: ['id', 'url', 'title', 'text'],
# num_rows: 3459
# })
# })
print(sum(len(t) for t in tyv_wiki['train']['text'])) # 7568832
print(sum(len(t) for t in trans_df.tyv.dropna())) # 3573803After that, I put all my text together and preprocess them. Then I count their characters, in order to force my tokenizer to include all the characters that appear at least 3 times (the characters that appear only once or twice won’t probably be learned by the model anyway). I also exclude the space, because it is always converted to an underscore character by sentencepiece.
from collections import Counter
all_texts = tyv_wiki['train']['text'] + df_train.tyv.dropna().tolist()
all_text_normalized = [preproc(t) for t in tqdm(all_texts)]
chars_cnt = Counter(c for t in all_text_normalized for c in t)
required_chars = ''.join([
k for k, v in chars_cnt.most_common()
if v >= 3 and k not in ' '
])I dump the texts into a plaintext file, and train a new sentencepiece tokenizer model on this file, in order to add its tokens to the existing NLLB tokenizer. Sentencepiece is one of the popular algorithms to train a tokenizer, and the NLLB tokenizer already has it under the hood.
I chose the vocabulary size to be 16384 intuitively, because such a number of tokens can potentially cover the most important roots and suffixes in the language (to compare: NLLB vocabulary for 200 languages has 256000 tokens, but many of them are used by a lot of different languages). All the other parameters are not very important.
This code executes for several minutes.
import sentencepiece as spm
all_texts_file = 'myv_texts_plain.txt'
SPM_PREFIX = 'spm_tyvan_16k'
with open(all_texts_file, 'w') as f:
for i, text in enumerate(all_texts):
print(text, file=f)
spm.SentencePieceTrainer.train(
input=all_texts_file,
model_prefix=SPM_PREFIX,
vocab_size=2**14, # 16K
character_coverage = 1,
num_threads=16,
train_extremely_large_corpus=False,
add_dummy_prefix=False,
max_sentencepiece_length=128,
max_sentence_length=4192*4,
pad_id=0,
eos_id=1,
unk_id=2,
bos_id=-1,
required_chars=required_chars,
)After training a Tyvan tokenizer, I perform a “surgical operation” with it: extracting the sentencepiece model from the standard NLLB tokenizer and enriching it from all tokens from the Tyvan tokenizer that have been missing from the NLLB tokenizer (based on the example from the sentencepiece repo).
from sentencepiece import sentencepiece_model_pb2 as sp_pb2_model
# At this step, the code may throw an error about protobuf. Do as it tells.
from transformers import NllbTokenizer
# reading the NLLB and the Tyvan sentencepiece models into a native format
tokenizer = NllbTokenizer.from_pretrained('facebook/nllb-200-distilled-600M')
sp_trained = spm.SentencePieceProcessor(model_file=f'{SPM_PREFIX}.model')
added_spm = sp_pb2_model.ModelProto()
added_spm.ParseFromString(sp_trained.serialized_model_proto())
old_spm = sp_pb2_model.ModelProto()
old_spm.ParseFromString(tokenizer.sp_model.serialized_model_proto())
# adding the missing tokens to the NLLB sentencepiece model
nllb_tokens_set = {p.piece for p in old_spm.pieces}
prev_min_score = old_spm.pieces[-1].score
for p in added_spm.pieces:
piece = p.piece
# !!! THIS FIX WAS ADDED LATER; it is required for CT2 compatibility !!!
# 1 is ordinary token, non-1 is special token; we don't want to copy the special tokens
if p.type != 1:
continue
if piece not in nllb_tokens_set:
new_p = sp_pb2_model.ModelProto().SentencePiece()
new_p.piece = piece
# for all new tokens, I'll set a lower score (priority)
new_p.score = p.score + prev_min_score
old_spm.pieces.append(new_p)
# saving the result to disk
NEW_SPM_NAME = 'spm_nllb_tyvan_268k.model'
with open(NEW_SPM_NAME, 'wb') as f:
f.write(old_spm.SerializeToString())Finally, I need to update the neural network weights: add new embeddings for the freshly added tokens. In NLLB, the token embeddings reside in the parameter called shared. It is used both in the encoder and decoder input embeddings and in the last decoder layer that predicts the distribution of the next token.
By default, the embeddings for the new tokens are initialized randomly. Instead, I re-initialize each one with the average of the embeddings of the old tokens that corresponded to the new token (or if there are none, with the embedding of the <unk> token). This slightly improves the training speed, because the newly created token embeddings are already informative.
from transformers import AutoModelForSeq2SeqLM
model_name = 'facebook/nllb-200-distilled-600M'
# loading the tokenizers
tokenizer_old = NllbTokenizer.from_pretrained(model_name)
tokenizer = NllbTokenizer.from_pretrained(model_name, vocab_file=NEW_SPM_NAME)
print(len(tokenizer_old), len(tokenizer)) # 256204, 268559
added_vocab = set(tokenizer.get_vocab()).difference(set(tokenizer_old.get_vocab()))
print(len(added_vocab)) # 12355
# loading and resizing the model
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
model.resize_token_embeddings(len(tokenizer))
# re-initializing the new embeddings
for t in tqdm(added_vocab):
tt = tokenizer_old(t, add_special_tokens=False).input_ids
if len(tt) == 0:
tt = [tokenizer_old.unk_token_id]
idx = tokenizer.convert_tokens_to_ids(t)
model.model.shared.weight.data[idx] = model.model.shared.weight.data[tt].mean(0)In the next steps of the tutorial, I will ignore the results of this optional step, and instead just continue from Step 2. But if you want to run vocabulary extension on your data, you can adapt my code from this notebook.
Step 4 (optional): Adding a new language tag
In a NLLB tokenizer, language tags are special: they are tokens prepended to the source and target texts, and the model uses them to correctly identify source and target languages. If fine-tune a NLLB model, you may want to add a new language tag to the model and the tokenizer. However, if any of the following is true, you can skip this step and instead go directly to Step 5:
- The languages that you are fine-tuning with are already included in the model;
- You will reuse one of the existing language tags for your new language;
- You are going to use the model only for a single pair of languages, so it can always just guess them from the source text.
The language tag tokens are not saved in the sentencepiece vocabulary; instead, they are stored in a hardcoded list. And this poses a problem when we try adding a new language token: the list is hardcoded (at least, for now).
To offset this problem, I write a function that re-runs a part of the tokenizer’s init code with a new language token. Unfortunately, calling this function once is not enough; you need to do this every time after you load the tokenizer from disk.
Disclaimer: when I was working on this code, I used the package version transformers<=4.33.
Later, I will publish an update that supports the newer versions.
def fix_tokenizer(tokenizer, new_lang='tyv_Cyrl'):
"""
Add a new language token to the tokenizer vocabulary
(this should be done each time after its initialization)
"""
old_len = len(tokenizer) - int(new_lang in tokenizer.added_tokens_encoder)
tokenizer.lang_code_to_id[new_lang] = old_len-1
tokenizer.id_to_lang_code[old_len-1] = new_lang
# always move "mask" to the last position
tokenizer.fairseq_tokens_to_ids["<mask>"] = len(tokenizer.sp_model) + len(tokenizer.lang_code_to_id) + tokenizer.fairseq_offset
tokenizer.fairseq_tokens_to_ids.update(tokenizer.lang_code_to_id)
tokenizer.fairseq_ids_to_tokens = {v: k for k, v in tokenizer.fairseq_tokens_to_ids.items()}
if new_lang not in tokenizer._additional_special_tokens:
tokenizer._additional_special_tokens.append(new_lang)
# clear the added token encoder; otherwise a new token may end up there by mistake
tokenizer.added_tokens_encoder = {}
tokenizer.added_tokens_decoder = {} I apply this function to the tokenizer, and it adds one new language token to it. Then I expand the embedding layer of the model accordingly, after which I need to patch the embeddings of the model, for two reasons:
- In NLLB vocabulary, for some unknown reason, the
<mask>token always goes after all the language codes, so if I add one more, the<mask>token also moves; thus, I move its embedding. - The embedding for the new token is by default initialized randomly, but instead I choose to initialize it with the language code for a similar language: Kyrgyz.
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model_name = "facebook/nllb-200-distilled-600M"
# loading the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# patching them
fix_tokenizer(tokenizer)
model.resize_token_embeddings(len(tokenizer))
# fixing the new/moved token embeddings in the model
added_token_id = tokenizer.convert_tokens_to_ids('tyv_Cyrl')
similar_lang_id = tokenizer.convert_tokens_to_ids('kir_Cyrl')
embeds = model.model.shared.weight.data
# moving the embedding for "mask" to its new position
embeds[added_token_id+1] =embeds[added_token_id]
# initializing new language token with a token of a similar language
embeds[added_token_id] = embeds[similar_lang_id]Now the model and the tokenizer are prepared for processing Tyvan . Of course, the model still needs some training to actually learn it.
Step 4 3/4, even more optional: adding a new language code when using later versions of the transformers library
As I mentioned above, this tutorial was based on a specific version of the package: transformers<=4.33. In 4.34, they refactored the code for NllbTokenizer (trying to fix the diabolic behaviour of added token encoders and decoders), so my code for adding a new language code to the tokenizer no longer worked with this version. In 4.38, they did another refactoring, which finally removed the hardcoded dependency of tokenizer on the hardcoded list of 202 languages. So after the version 4.38, my hack fix_tokenizer that we had to call on each tokenizer initialization is no longer needed!
However, after some of those updates, the added tokens encoder and decoder became more stubborn — and now there is no obvious way to update them other than removing them and adding them again. This is done automatically when loading the tokenizer from disk — but we have to remove a few files first. The code looks more or less like this:
import json
import os
import shutil
from typing import List, Tuple
from transformers import NllbTokenizer
from transformers.models.nllb.tokenization_nllb import FAIRSEQ_LANGUAGE_CODES
def update_nllb_tokenizer(
old_tokenizer: NllbTokenizer,
new_spm_path: str,
new_lang_codes: List[str],
) -> NllbTokenizer:
"""
Create a new tokenizer for NLLB, with an updated sentencepiece model and some new language codes.
In order to get rid of the old (and wrong) added token encoders/decoders, we save the tokenizer to disk and remove those files.
:param old_tokenizer: the original tokenizer
:param new_spm_path: path to the file with the sentncepiece model
:param new_lang_codes: list of the new codes to add to the tokenizer
:return:
"""
TKN_DIR = "old_tokenizer" # todo: make it a temp dir
old_tokenizer.save_pretrained(TKN_DIR)
with open(f"{TKN_DIR}/tokenizer_config.json", "r") as f:
cfg = json.load(f)
cfg["added_tokens_decoder"] = {
k: v
for k, v in cfg["added_tokens_decoder"].items()
if k in ["0", "1", "2", "3"]
}
cfg["additional_special_tokens"] = []
with open(f"{TKN_DIR}/tokenizer_config.json", "w") as f:
json.dump(cfg, f, indent=2)
# this contains added tokens: language codes and mask
os.remove(f"{TKN_DIR}/added_tokens.json")
os.remove(f"{TKN_DIR}/special_tokens_map.json")
os.remove(f"{TKN_DIR}/sentencepiece.bpe.model")
shutil.copy(new_spm_path, f"{TKN_DIR}/sentencepiece.bpe.model")
new_tokenizer = NllbTokenizer.from_pretrained(
TKN_DIR,
additional_special_tokens=sorted(FAIRSEQ_LANGUAGE_CODES + new_lang_codes),
)
return new_tokenizerThis code should be called only once: when you are updating the tokenizer for the first time. Any time you use it later, it will be alright. At least, until the transformers library introduces some other changes in its code.
Step 5: Training the model
One way to organize the training is to follow the translation tutorial by HF: preprocess the whole dataset at once and feed it to a Seq2SeqTrainer . However, I prefer a custom training loop (which can be made more robust to out-of-memory errors) and creating training batches on the fly.
To save some GPU memory, I use Adafactor optimizer instead of the more popular AdamW. I train the model with a learning rate linearly increasing from zero for the first 1000 steps, and then staying at 0.0001. I set a weight_decay to prevent the model parameters from becoming too big, and use a clip_threshold for restricting the norm of the gradient to stabilize the training.
from transformers.optimization import Adafactor
from transformers import get_constant_schedule_with_warmup
model.cuda();
optimizer = Adafactor(
[p for p in model.parameters() if p.requires_grad],
scale_parameter=False,
relative_step=False,
lr=1e-4,
clip_threshold=1.0,
weight_decay=1e-3,
)
scheduler = get_constant_schedule_with_warmup(optimizer, num_warmup_steps=1000)To create each training batch, I randomly choose the translation direction (Tyvan to Russian or reverse), and randomly sample the sentence pairs. For more advanced training, I could also apply some random data augmentation to them (e.g. replacing words or changing the orthography).
import random
LANGS = [('ru', 'rus_Cyrl'), ('tyv', 'tyv_Cyrl')]
def get_batch_pairs(batch_size, data=df_train):
(l1, long1), (l2, long2) = random.sample(LANGS, 2)
xx, yy = [], []
for _ in range(batch_size):
item = data.iloc[random.randint(0, len(data)-1)]
xx.append(preproc(item[l1]))
yy.append(preproc(item[l2]))
return xx, yy, long1, long2
print(get_batch_pairs(1))
# (['чеди'], ['семь'], 'tyv_Cyrl', 'rus_Cyrl') Sometimes, training is interrupted because GPU runs out of memory (either because the texts in the batch are too long or because of some memory not being cleaned). To make the training more robust to them, I create a function that tries to release some memory:
import gc
import torch
def cleanup():
"""Try to free GPU memory"""
gc.collect()
torch.cuda.empty_cache()I set some more parameters before training:
batch_size = 16 # 32 already doesn't fit well to 15GB of GPU memory
max_length = 128 # token sequences will be truncated
training_steps = 60000 # Usually, I set a large number of steps,
# and then just interrupt the training manually
losses = [] # with this list, I do very simple tracking of average loss
MODEL_SAVE_PATH = '/gd/MyDrive/models/nllb-rus-tyv-v1' # on my Google driveNow we are ready for the training loop! To be robust, we save the model every 1000 steps, and after each out-of-memory error, we just ignore it and continue the training. If there are too many OOMs, though, you may want to interrupt the useless training and reduce the batch_size or max_length.
model.train()
x, y, loss = None, None, None
cleanup()
tq = trange(len(losses), training_steps)
for i in tq:
xx, yy, lang1, lang2 = get_batch_pairs(batch_size)
try:
tokenizer.src_lang = lang1
x = tokenizer(xx, return_tensors='pt', padding=True, truncation=True, max_length=max_length).to(model.device)
tokenizer.src_lang = lang2
y = tokenizer(yy, return_tensors='pt', padding=True, truncation=True, max_length=max_length).to(model.device)
# -100 is a magic value ignored in the loss function
# because we don't want the model to learn to predict padding ids
y.input_ids[y.input_ids == tokenizer.pad_token_id] = -100
loss = model(**x, labels=y.input_ids).loss
loss.backward()
losses.append(loss.item())
optimizer.step()
optimizer.zero_grad(set_to_none=True)
scheduler.step()
except RuntimeError as e: # usually, it is out-of-memory
optimizer.zero_grad(set_to_none=True)
x, y, loss = None, None, None
cleanup()
print('error', max(len(s) for s in xx + yy), e)
continue
if i % 1000 == 0:
# each 1000 steps, I report average loss at these steps
print(i, np.mean(losses[-1000:]))
if i % 1000 == 0 and i > 0:
model.save_pretrained(MODEL_SAVE_PATH)
tokenizer.save_pretrained(MODEL_SAVE_PATH)An advantage of such a training loop is that you can interrupt it at any moment and adjust something or take a look at how the current version of the model can translate a sample sentence. But of course, you can replace it with something more sophisticated, if you feel like it.
I usually run the training on Google Colab for at most 24 hours, and then Colab shuts it down. If I want to train longer, I restart the notebook, load the model from my last checkpoint, and just continue training it the same way as before. But for teaching NLLB a new language similar to the ones that it already knows, 24 hours is more than enough.
Step 6: Evaluating and using the model
After the model has been trained for some time, you can test how well it translates. If the Colab instance has shut down, you can always load it back from the Google drive where you have saved it:
from transformers import NllbTokenizer, AutoModelForSeq2SeqLM
model_load_name = '/gd/MyDrive/models/nllb-rus-tyv-v1'
model = AutoModelForSeq2SeqLM.from_pretrained(model_load_name).cuda()
tokenizer = NllbTokenizer.from_pretrained(model_load_name)
fix_tokenizer(tokenizer)Here is an example of function that can serve for translation:
def translate(
text, src_lang='rus_Cyrl', tgt_lang='eng_Latn',
a=32, b=3, max_input_length=1024, num_beams=4, **kwargs
):
"""Turn a text or a list of texts into a list of translations"""
tokenizer.src_lang = src_lang
tokenizer.tgt_lang = tgt_lang
inputs = tokenizer(
text, return_tensors='pt', padding=True, truncation=True,
max_length=max_input_length
)
model.eval() # turn off training mode
result = model.generate(
**inputs.to(model.device),
forced_bos_token_id=tokenizer.convert_tokens_to_ids(tgt_lang),
max_new_tokens=int(a + b * inputs.input_ids.shape[1]),
num_beams=num_beams, **kwargs
)
return tokenizer.batch_decode(result, skip_special_tokens=True)
# Example usage:
t = 'мөңгүн үр чыткаш карарар'
print(translate(t, 'tyv_Cyrl', 'rus_Cyrl'))
# ['серебро от времени чернеет']It has several important parameters:
num_beams: increasing this number usually improves the accuracy, but makes the translation slower and increases the memory consumption.aandbcontrol the maximal length of the generated text (in tokens); setting them to smaller values can speed up the translation, but may occasionally lead to undertranslation.
The transformers package has many other parameters that you can modify when translating texts; please read the generation strategies doc to learn about them.
This way, we can generate the translations for our development dataset (both rus-tyv and tyv-rus), and take a look at how accurate they are.

From the sample, it looks like the machine translations match the references (for tyv_translated, the reference is tyv, and for rus_translated, it is ru) in about 50% cases. How can we quantify this intuitive quality measure automatically?
The two most popular automatic metrics for machine translation quality are BLEU and ChrF++. Both of them compute a percentage similarity between the translation and the reference texts. However, they define the similarity slightly differently; e.g. BLEU reward only full-word matches, while ChrF++ gives positive scores even when only word parts match (so e.g. ChrF++ would treat the translation “течёт холод” to have similarity to the reference “несёт холодом” about 40%, while BLEU would report a zero similarity).
With these metrics, we can assign some numeric values to the quality of our translation model:
import sacrebleu
bleu_calc = sacrebleu.BLEU()
chrf_calc = sacrebleu.CHRF(word_order=2) # this metric is called ChrF++
print(bleu_calc.corpus_score(df_dev['rus_translated'].tolist(), [df_dev['ru'].tolist()]))
print(chrf_calc.corpus_score(df_dev['rus_translated'].tolist(), [df_dev['ru'].tolist()]))
print(bleu_calc.corpus_score(df_dev['tyv_translated'].tolist(), [df_dev['tyv'].tolist()]))
print(chrf_calc.corpus_score(df_dev['tyv_translated'].tolist(), [df_dev['tyv'].tolist()]))
# BLEU = 24.14 52.5/30.4/18.9/12.1 (BP = 0.981 ratio = 0.981 hyp_len = 2281 ref_len = 2324)
# chrF2++ = 49.49
# BLEU = 23.41 52.1/31.0/18.9/11.3 (BP = 0.966 ratio = 0.967 hyp_len = 2292 ref_len = 2371)
# chrF2++ = 50.89BLEU and ChrF++ are useful for comparing the quality of different models on the same dataset. However, comparing their values for different target languages (or even for the same language, but using different data) is not so meaningful. For example, the table below doesn’t tell in which direction (tyv-rus or rus-tyv) the model is better. But it tells that in all cases, applying beam search is better than not applying it, and that in most cases, Model v2 is better than Model v1.
| tyv->rus | rus->tyv
Model v1 (no vocabulary update): |
no beam search | 23.21 | 22.03
num_beams = 4 | 24.14 | 23.41
Model v2 (extended vocabulary): |
no beam search | 24.08 | 22.50
num_beams = 4 | 25.18 | 23.22But wait, what on Earth is Model v2? Actually, it is a version of Model v1 for which I did go over the optional Step 3 of expanding the vocabulary. As you can see, this step provides a small but sustainable gain in quality, at the cost of additional complexity and increasing the model size.
A tip: If you need to translate a long text, you should always split it into individual sentences and process them one by one (for many European languages, you can use the sentence-splitter Python package; for other languages, you can look at the text preprocessing code by the NLLB team). Otherwise, there is a risk that the model will only translate a few input sentences and ignore the rest (users keep compaining about it, e.g. 1, 2, 3), because its training data consisted mostly of individual sentences.
Another tip: If you want to translate multiple sentences using a GPU, it would be faster if you group them into batches which are translated in parallel. Translating a batch takes as long as translating the longest sentence in it, so it would make sense to group batches by length:
def batched_translate(texts, batch_size=16, **kwargs):
"""Translate texts in batches of similar length"""
idxs, texts2 = zip(*sorted(enumerate(texts), key=lambda p: len(p[1]), reverse=True))
results = []
for i in trange(0, len(texts2), batch_size):
results.extend(translate(texts2[i: i+batch_size], **kwargs))
return [p for i, p in sorted(zip(idxs, results))]Step 7: Publishing
We will push the model and the tokenizer to a repository on the HuggingFace space, so that the other users could easily find and download them. This is very simple, as long as you have a HF account.
To connect to this account from a Colab notebook, you can type:
!huggingface-cli loginYou will be prompted to go to https://huggingface.co/settings/tokens and copy-paste an authorization token from there. After that, you can execute the following code to create a repo for your model:
upload_repo = "slone/nllb-rus-tyv-v1"
tokenizer.push_to_hub(upload_repo)
model.push_to_hub(upload_repo)In a few minutes, the model and the tokenizer will be uploaded to a new repo like this one: https://huggingface.co/slone/nllb-rus-tyv-v1 (instead of slone, your should use the name of your HF personal or organization account). By the way, the repo for the v2 model is https://huggingface.co/slone/nllb-rus-tyv-v2-extvoc.
As the last step, you will need to press the “Create model card” button and type some useful information about your model (please read here about it). In particular, indicate the supported languages and choose the cc-by-nc-4.0 license; this is the license with which the NLLB models were distributed, so all the derivative models must inherit it.
In addition to just publishing the model and writing its description, you can host an interactive demo application on the HF platform. Thanks to the magic of packages such as Gradio or Streamlit, this requres not much more that just writing the function that translates a text.
You can copy such a demo from https://huggingface.co/spaces/slone/nllb-rus-tyv-v1-demo, and adapt the path to the model, supported languages, and the description text in its app.py file.
Step 8: (Optional) Serving the model with Docker
Having a demo hosted for free at the HuggingFace website is good. But what if you want to use it elsewhere? The model is rather big (about 2.5GB), and it requires a lot of compute, so the only realistic option is to run it as a micro-service on some powerful server.
Such services are often run with Docker. I do the same, and I create a very simple web API using the FastAPI package. Here is the repository with the minimal working code: https://github.com/slone-nlp/nllb-docker-demo.
This code consists of a Dockerfile and two Python files. The file translation.py defines a Translator class, which is a wrapper that encapsulates model , tokenizer, and the translate function; everything that we have already seen. The file main.py defines a web API, implemented with FastAPI. It defines two endpoints: /translate, for running the translation, and /list-languages, for telling the potential frontend what languages are available:
from fastapi import FastAPI
from pydantic import BaseModel
from translation import Translator
class TranslationRequest(BaseModel):
text: str
src_lang: str = 'rus_Cyrl'
tgt_lang = 'tyv_Cyrl'
app = FastAPI()
translator = Translator()
@app.post("/translate")
def translate(request: TranslationRequest):
"""
Perform translation with a fine-tuned NLLB model.
The language codes are supposed to be in 8-letter format, like "eng_Latn".
Their list can be returned by /list-languages.
"""
output = translator.translate(request.text, src_lang=request.src_lang, tgt_lang=request.tgt_lang)
return {"translation": output}
@app.get("/list-languages")
def list_languages():
"""Show the mapping of supported languages: from their English names to their 8-letter codes."""
return translator.languagesTo run the application, you need to execute two commands in the command line (assuming that you have already started Docker), from the nllb-docker-demo directory:
docker build -t nllb .
docker run -it -p 7860:7860 nllbThe first command will take a few minutes to build the image, but once it is built, the second command runs quite fast. Upon completion, it will run a web server that supports the endpoints defined above. As a bonus, FastAPI creates an endpoint with automatic documentation: http://localhost:7860/docs. It will show you the signatures of the endpoints, and will let you test both of them just from the browser.
As a direct test of the API, you can open http://localhost:7860/list-languages in your browser, and see the returned list of languages as a JSON object: {"Russian": "rus_Cyrl", "Tyvan": "tyv_Cyrl"}.
The /translate endpoint supports only POST requests, so you can’t easily test it with a browser. But you can test it e.g. with the curl tool:
curl -X 'POST' \
'http://localhost:7860/translate' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{"text": "Нет войне!", "src_lang": "rus_Cyrl", "tgt_lang": "tyv_Cyrl"}'(if you use Windows, you’ll have to write the command without \, in a single line, with ' replaced by " and " in the JSON body replaced by \")
curl -X "POST" http://localhost:7860/translate -H "Content-Type: application/json" -d "{\"text\": \"Нет войне!\", \"src_lang\": \"rus_Cyrl\", \"tgt_lang\": \"tyv_Cyrl\"}"The command will call the translation service and return a JSON response:
{"translation":"Дайын-чаа чок!"}You can deploy this backend application on some virtual server (e.g. AWS or DigitalOcean), and make your frontend app (e.g. a mobile application or a web frontend written in JS) talk to the backend with this API.
What next?
In this tutorial, I have shown how to examine a training dataset for machine translation, how to update the NLLB tokenizer with new tokens and a new language code, how to fine-tune a NLLB model, and how to publish and serve it.
This should be enough for creating a proof-of-concept machine translation service for a new language. However, there are some problems that I didn’t cover here (but may address in some future tutorials):
- How to collect a parallel dataset for a new language from existing sources (some tips are in my paper about machine translation for Erzya)
- How to organize manual translation to create even more parallel texts
- How to clean and filter the existing parallel data (some tips are in my post about Bashkir corpus cleaning, in Russian)
- How to prevent the model from forgetting other languages (the one in this tutorial has learned to translate only between Russian and Tyvan, but forgot how to translate into English)
- How to decrease the model size (e.g. quantization and distillation), to make its deployment more affordable and faster. For example, ctranslate2 can quantize your model from
float32toint8, which makes it 4 times smaller and 4 times faster, without significantly sacrificing the translation quality. - How to create an advanced machine translation system, robust both in terms of high load and translation quality.
If you want to contact me on any of these issues (or on some other), don’t hesitate to leave your comments here, or to write directly to my Telegram (@cointegrated). You can also subscribe to my channel about NLP (in Russian): https://t.me/izolenta_mebiusa.
And one last appeal: if you have data or models for lower-resourced languages, please publish them! Meta did a wonderful job by publishing the NLLB-200 models, but only as a community, we can truly make no language left behind, even if we address them just one at a time.