David DaleHow to fine-tune a NLLB-200 model for translating a new languageNLLB is a translation model that supports 200 languages. I teach it one more language, Tyvan, and explain the code behind this update.25 min read·Oct 17, 2023--4--4
David DaleinTowards Data ScienceCompressing unsupervised fastText modelsA python package to reduce word embeddings models by 300 times, with almost the same performance on downstream NLP tasks.6 min read·Dec 14, 2021--1--1
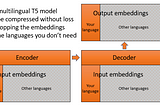
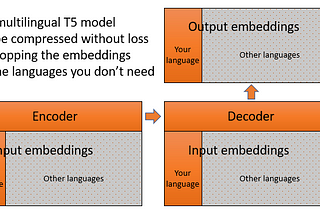
David DaleinTowards Data ScienceHow to adapt a multilingual T5 model for a single languageLoad embeddings only for the tokens from your language to reduce model size4 min read·May 4, 2021--7--7
David DaleDo you have to try to love math?If you don’t like and don’t understand math, does it mean you are stupid? Do you need to love math to achieve at…6 min read·Feb 13, 2018----
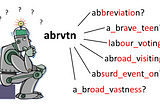
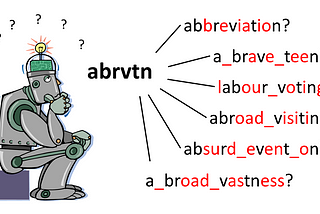
David DaleinThe StartupA machine learning model to understand fancy abbreviations, trained on TolkienRecently I bumped into a question on Stackoverflow, how to recover phrases from abbreviations, e.g. turn “wtrbtl” into “water bottle”, and…9 min read·Jan 14, 2018--5--5